项目 02 · DCR TRIAGE AGENT方案展示 · 核心流程完整
企业需求分诊智能体
面向 Teams / M365 PM 的设计变更请求分诊工作流,将客户请求转成可审阅的 PM 决策建议。
需求分诊风险边界重复识别建议回复
用户痛点
- 企业客户需求数量多、质量不一,PM 需要快速判断是否真的是 DCR。
- 重复需求、缺信息请求和需要升级的请求混在一起,处理口径难统一。
产品方案
- 构建安全边界检查、请求类型判断、重复诉求识别、建议回复和升级判断 pipeline。
- 将 PM 的判断类型结构化,输出带理由、证据和下一步建议的分诊结果。
我的角色
- 抽象需求分诊流程和判断类型,设计 Agent 输出结构。
- 整理 PRD、PPT、架构材料,支撑内部试用和方案说明。
下一步:继续优化分类置信度、重复识别解释性和 PM feedback 回流机制。
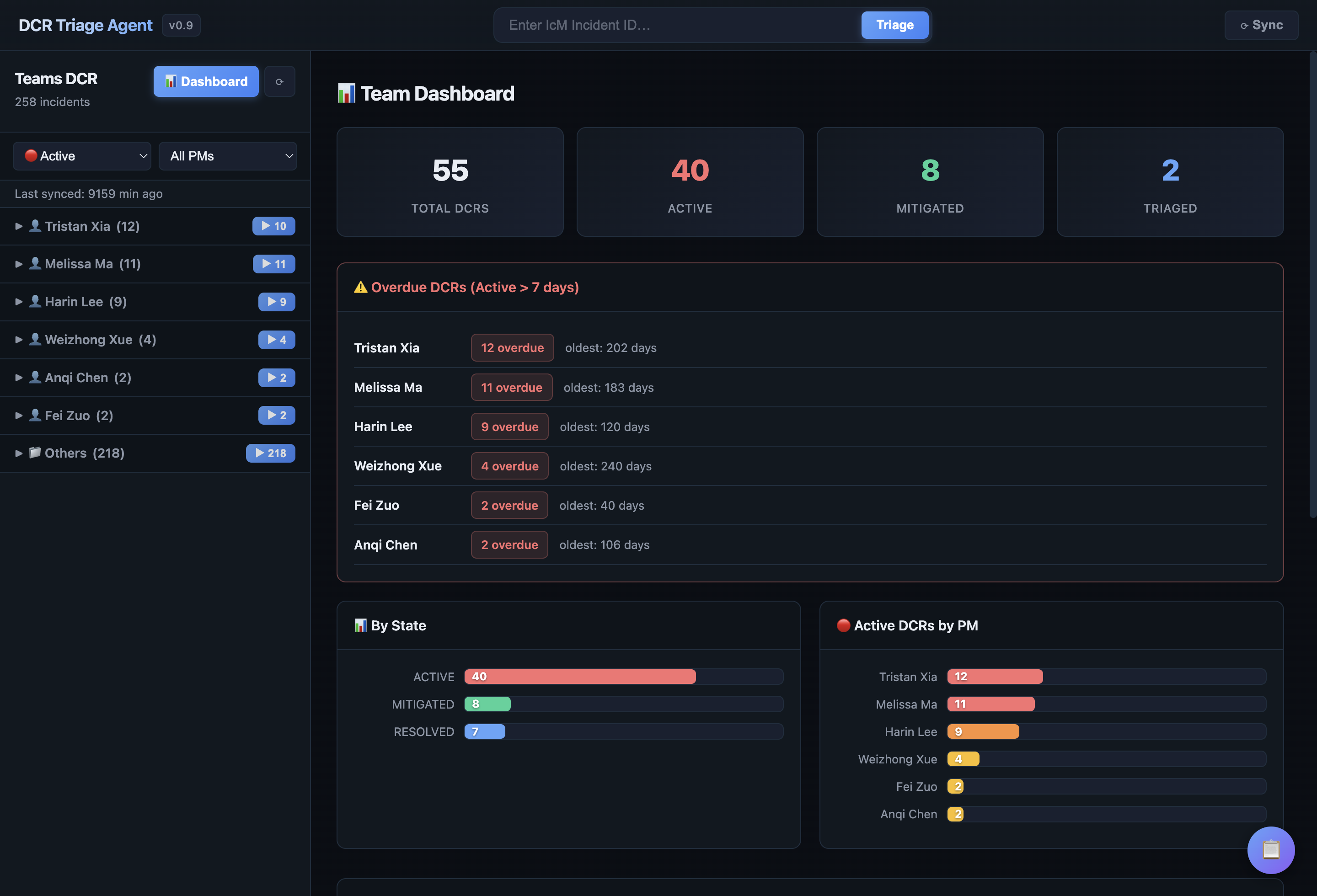
DCR
设计变更请求
5-step
分诊判断流程
PM
审阅式辅助